========= basic ========== left : h right : l up : k down : j undo the previous motion: u undo the previous motion of the line : U undo undo : ctrl+R word : w end : e insert : i append : a paste : p replace a char :r replace a word : R copy a word: yw (paste is p!!) copy some words : v+y show the numbers of line : set number to the line end : $ command prompt : ctrl + d / tab ($ is means the end of the line) (w is means word) (e is means end) ======== delete ========== d+motion delete a char: x delete to word : dw delete to end : de left delete : dj right delete : dl delete to line : d$ delete line : dd ======= number to execute ===== move to second word : 2w move to second word end : 2e to the end of the line : 0 delete 2 words : d2w delete 2 lines : 2dd ======= the command of place ===== delete a line and paste it below the current line : dd + p replace a word : r + word change a word to the end of the word : cw/ce change to the end of the row : c$ change to second word : c2w ======= location and file status ===== go to the first line : gg go to the last line : G show file status : ctrl+g ====== search command ========== search word in order : /+word (n:next one ;N:the previous one) search word in reverse : ?+word find matched brackets(查找匹配的括号) : % replace word in this line : :/s/oldword/newword replace word all : :/s/oldword/newword/g replace word all and confirm everyone : :/s/oldword/newword/gc replace word between line1 and line3 : :1,3/oldword/newword/g ====== others ========= use external instruction in vim : :!+commad(eg: :!ls) save file in another file : :w+filename(eg: :w test) merge other file in this file : :r + filename(insert to now location) insert mode insert line under the line : o insert line upon the line : O
Traceback (most recent call last): File "LineLossRate.py", line 237, in <module> dfjoin.show(5) File "/opt/cloudera/parcels/SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012/lib/spark2/python/lib/pyspark.zip/pyspark/sql/dataframe.py", line 378, in show File "/opt/cloudera/parcels/SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012/lib/spark2/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py", line 1257, in __call__ File "/opt/cloudera/parcels/SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012/lib/spark2/python/lib/pyspark.zip/pyspark/sql/utils.py", line 63, in deco File "/opt/cloudera/parcels/SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012/lib/spark2/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py", line 328, in get_return_value py4j.protocol.Py4JJavaError: An error occurred while calling o409.showString. : org.apache.spark.SparkException: Could not execute broadcast in 1800 secs. You can increase the timeout for broadcasts via spark.sql.broadcastTimeout or disable broadcast join by setting spark.sql.autoBroadcastJoinThreshold to -1 at org.apache.spark.sql.execution.exchange.BroadcastExchangeExec.doExecuteBroadcast(BroadcastExchangeExec.scala:150) at org.apache.spark.sql.execution.InputAdapter.doExecuteBroadcast(WholeStageCodegenExec.scala:387) at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeBroadcast$1.apply(SparkPlan.scala:144)
在其他节点上显示有一些重复连接超时的警告:
1 2 3 4 5 6 7 8 9 10 11
21/07/02 19:13:42 WARN scheduler.TaskSetManager: Lost task 9.0 in stage 70.0 (TID 5771, cdh06.nari.com, executor 12): java.net.ConnectException: Connection timed out (Connection timed out) at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:589) at java.net.Socket.connect(Socket.java:538) at java.net.Socket.<init>(Socket.java:434) at java.net.Socket.<init>(Socket.java:244) at org.apache.spark.api.python.PythonWorkerFact
2.2 报错代码
1 2 3 4 5 6 7 8
dfjoin=df365.join(resDf3,on=["xx"]).\ withColumn("xx",F.lit(dateMyes)). \ withColumn("xx", F.expr("cast(`xx` as string)")).join(tg_id,on=["xx"]).\ withColumnRenamed("xx","xx").\ select("xx","xx","xx""xx""xx""xx""xx").persist()
You can increase the timeout for broadcasts via spark.sql.broadcastTimeout or disable broadcast join by setting spark.sql.autoBroadcastJoinThreshold to -1
先来看看这样一条SQL语句:select * from order,item where item.id = order.i_id,很简单一个Join节点,参与join的两张表是item和order,join key分别是item.id以及order.i_id。现在假设这个Join采用的是hash join算法,整个过程会经历三步:
Exception: Python in worker has different version 3.5 than that in driver 3.6, PySpark cannot run with different minor versions.Please check environment variables PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON are correctly set.
def fun_one(): start = time() sleep(1) end = time() cost_time = end - start print("func one run time {}".format(cost_time)) def fun_two(): start = time() sleep(1) end = time() cost_time = end - start print("func two run time {}".format(cost_time))
def run_time(func): def wrapper(): start = time() func() # **函数在这里运行** end = time() cost_time = end - start print("func three run time {}".format(cost_time)) return wrapper
#测试tfGPU是否能够使用: import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' print('GPU', tf.test.is_gpu_available()) a = tf.constant(2.0) b = tf.constant(4.0) print(a + b)
from IPython.utils import io from google.colab import drive import psutil import humanize import os with io.capture_output() as captured: install_dependencies() print("Dependencies installed.")
import GPUtil as GPU printm()
1 2 3 4 5 6 7
#@title Set Time Zone !rm /etc/localtime !ln -s /usr/share/zoneinfo/HST /etc/localtime !date
#above is for HST, you can find yours in #/usr/share/zoneinfo
1
! rm -rf ./drive
1 2 3 4
#@title Mount Google Drive
from google.colab import drive drive.mount('/content/drive', force_remount=True)
1 2 3 4
#@title Cleanup folders if needed
!rm -r face_a !rm -r face_b
1 2 3 4 5 6 7 8 9
#@title Download training data !cp "/content/drive/My Drive/colab_files/faceswap/faces/face_a.zip" . !cp "/content/drive/My Drive/colab_files/faceswap/faces/face_b.zip" .
#@title Install Tensorflow !pip install -r faceswap/requirements_nvidia.txt #@ 这里会报错“ERROR: albumentations 0.1.12 has requirement imgaug<0.2.7,>=0.2.5, but you'll have imgaug 0.2.9 which is incompatible.” 但没关系
#@title 查看结果: Setting Faceswap backend to NVIDIA 09/26/2020 16:14:02 INFO Log level set to: INFO Using TensorFlow backend. 09/26/2020 16:14:04 INFO Model A Directory: /content/face_a/faceA 09/26/2020 16:14:04 INFO Model B Directory: /content/face_b/faceB 09/26/2020 16:14:04 INFO Training data directory: /content/drive/My Drive/colab_files/faceswap/models/model 09/26/2020 16:14:04 INFO =================================================== 09/26/2020 16:14:04 INFO Starting 09/26/2020 16:14:04 INFO Press 'ENTER' to save and quit 09/26/2020 16:14:04 INFO Press 'S' to save model weights immediately 09/26/2020 16:14:04 INFO =================================================== 09/26/2020 16:14:05 INFO Loading data, this may take a while... 09/26/2020 16:14:05 INFO Loading Model from Dlight plugin... 09/26/2020 16:14:05 INFO Using configuration saved in state file 09/26/2020 16:14:10 INFO Loaded model from disk: '/content/drive/My Drive/colab_files/faceswap/models/model' 09/26/2020 16:14:10 INFO Loading Trainer from Original plugin... 09/26/2020 16:14:12 INFO Enabled TensorBoard Logging [16:14:27] [#04386] Loss A: 0.05719, Loss B: 0.05088 09/26/2020 16:14:32 INFO [Saved models] - Average since last save: face_loss_A: 0.05719, face_loss_B: 0.05088 [16:19:42] [#04746] Loss A: 0.04279, Loss B: 0.03795 09/26/2020 16:19:46 INFO [Saved models] - Average since last save: face_loss_A: 0.04535, face_loss_B: 0.04580 [16:25:01] [#05106] Loss A: 0.04427, Loss B: 0.04492 09/26/2020 16:25:06 INFO [Saved models] - Average since last save: face_loss_A: 0.04406, face_loss_B: 0.04483 [16:25:19] [#05120] Loss A: 0.04438, Loss B: 0.03987
# Form implementation generated from reading ui file 'untitled.ui' # # Created by: PyQt5 UI code generator 5.15.0 # # WARNING: Any manual changes made to this file will be lost when pyuic5 is # run again. Do not edit this file unless you know what you are doing.
from PyQt5.QtWidgets import * from PyQt5 import QtCore, QtWidgets from datetime import datetime import datetime as datetime0 # 添加这一行可以在程序捕获异常的时候pyqt不崩溃 import cgitb cgitb.enable( format = 'text')
# Unique server id for this Neo4j instance # can not be negative id and must be unique ha.server_id=1 # List of other known instances in this cluster # Alternatively, use IP addresses: ha.initial_hosts=xxx.xx.xxx.100:5001,xxx.xx.xxx.102:5001,xxx.xx.xxx.9:5001(这里根据实际id进行修改,端口默认不变) # HA - High Availability # SINGLE - Single mode, default. dbms.mode=HA # HTTP Connector dbms.connector.http.enabled=true dbms.connector.http.listen_address=:7474 # 设置堆内存和页面缓存大小 dbms.memory.heap.initial_size=10g dbms.memory.heap.max_size=10g dbms.memory.pagecache.size=10g
[root@ng1 nebula]# ./jiqunRestart.sh Processing Meta Service ... start ng1 The authenticity of host 'ng1 (::1)' can't be established. ECDSA key fingerprint is SHA256:A1I43wcavqxvxEqTh2XYzqdYlXZZVbavUpmoQffE26Y. ECDSA key fingerprint is MD5:5d:9c:99:d7:70:51:5f:f0:e5:c7:cc:0d:54:e5:b6:f9. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'ng1' (ECDSA) to the list of known hosts. root@ng1's password: start ng2 The authenticity of host 'ng2 (192.168.111.133)' can't be established. ECDSA key fingerprint is SHA256:A1I43wcavqxvxEqTh2XYzqdYlXZZVbavUpmoQffE26Y. ECDSA key fingerprint is MD5:5d:9c:99:d7:70:51:5f:f0:e5:c7:cc:0d:54:e5:b6:f9. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'ng2,192.168.111.133' (ECDSA) to the list of known hosts. root@ng2's password: Processing Storage Service ... start ng1 root@ng1's password: start ng2 root@ng2's password: Processing Graph Service ... start ng1 root@ng1's password: start ng2 root@ng2's password:
这一步可能会出现“ERROR: Couldn’t connect to Docker daemon at http+docker://localhost - is it running? If it’s at a non-standard location, specify the URL with the DOCKER_HOST environment variable.的问题”,是因为需要给用户登录,直接su给root权限启动就可以了
1.1.4 问题4:打包报错“ File “sklearn/metrics/pairwise_fast.pyx”, line 1, in init sklearn.metrics.pairwise_fast ImportError: No module named ‘sklearn.utils._cython_blas’”
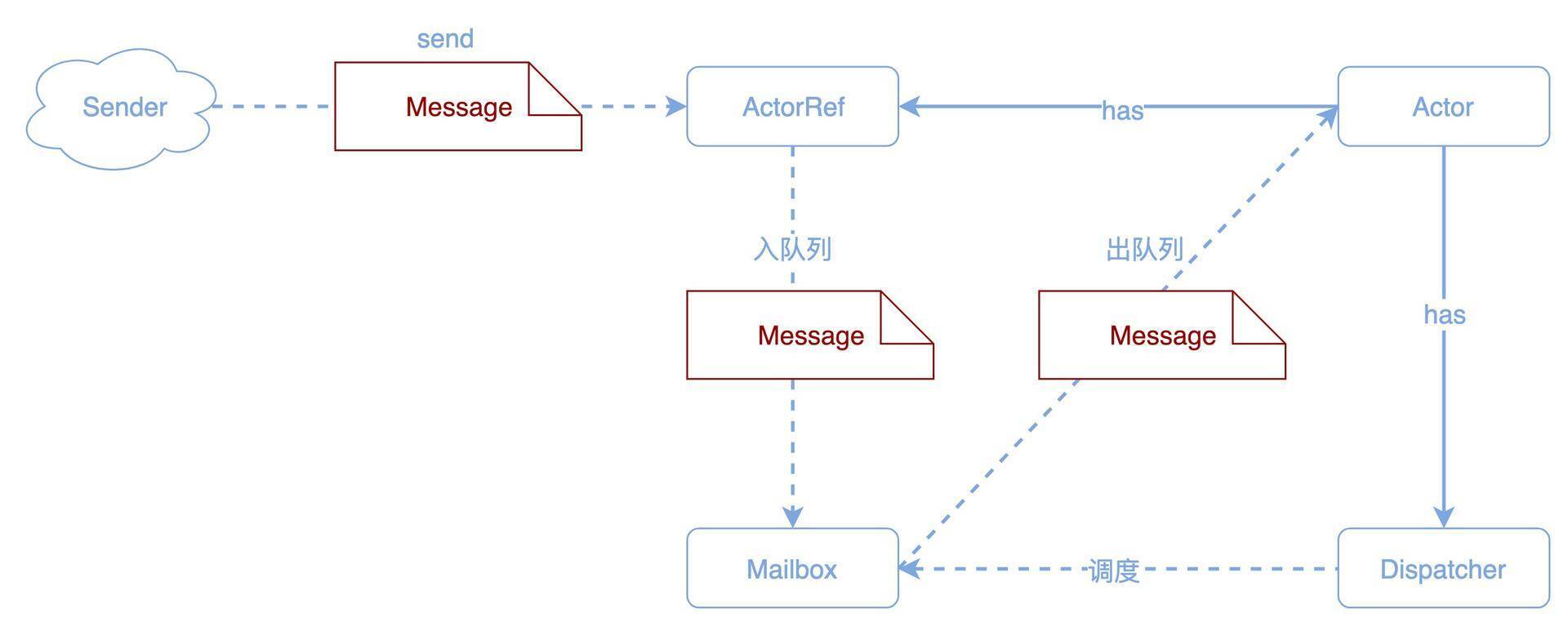
Akka 使用一种叫 Actor 的编程模型,Actor 编程模型是和面向对象编程模型平行的一种编程模型。面向对象认为一切都是对象,对象之间通过消息传递,也就是方法调用实现复杂的功能。
而 Actor 编程模型认为一切都是 Actor,Actor 之间也是通过消息传递实现复杂的功能,但是这里的消息是真正意义上的消息。不同于面向对象编程时,方法调用是同步阻塞的,也就是被调用者在处理完成之前,调用者必须阻塞等待;给 Actor 发送消息不需要等待 Actor 处理,消息发送完就不用管了,也就是说,消息是异步的。
 ]]>
]]>


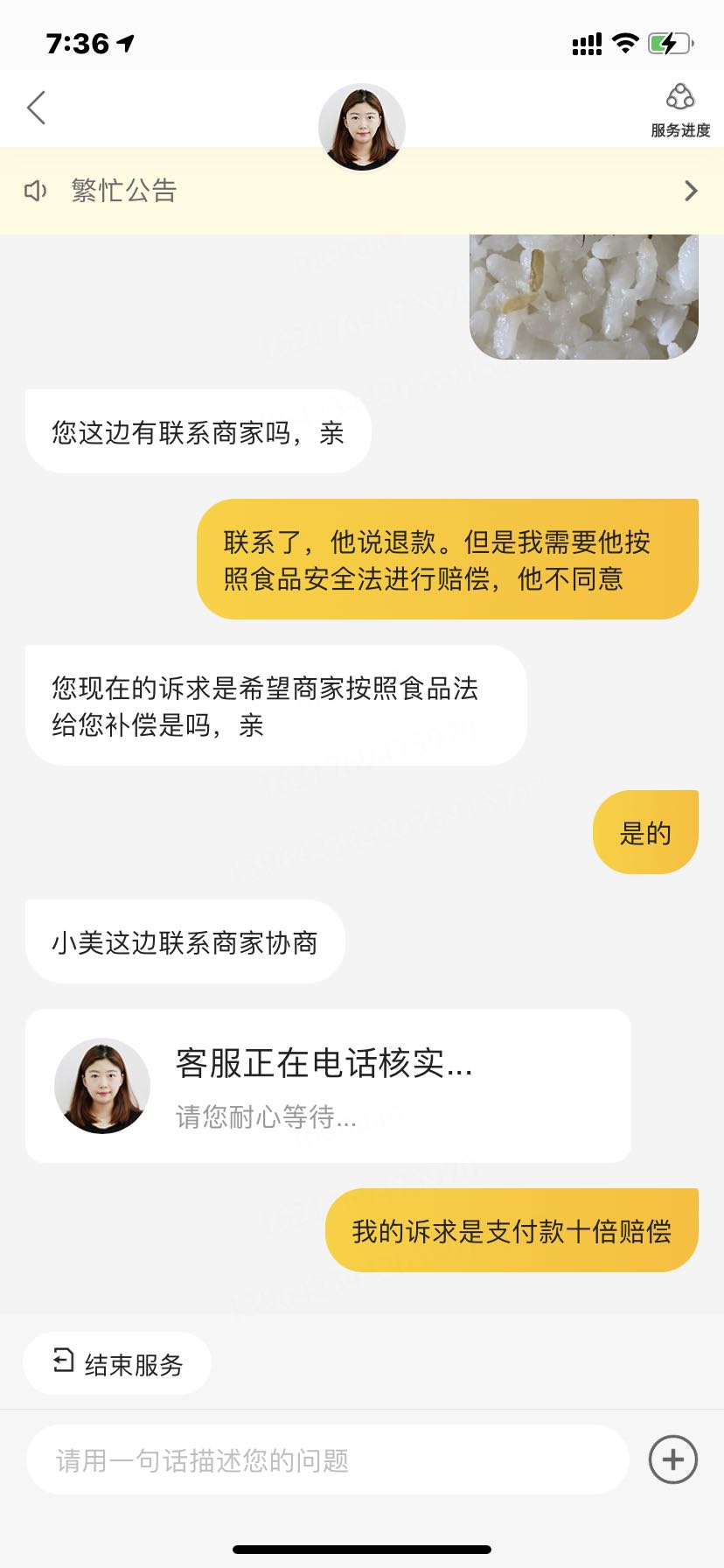
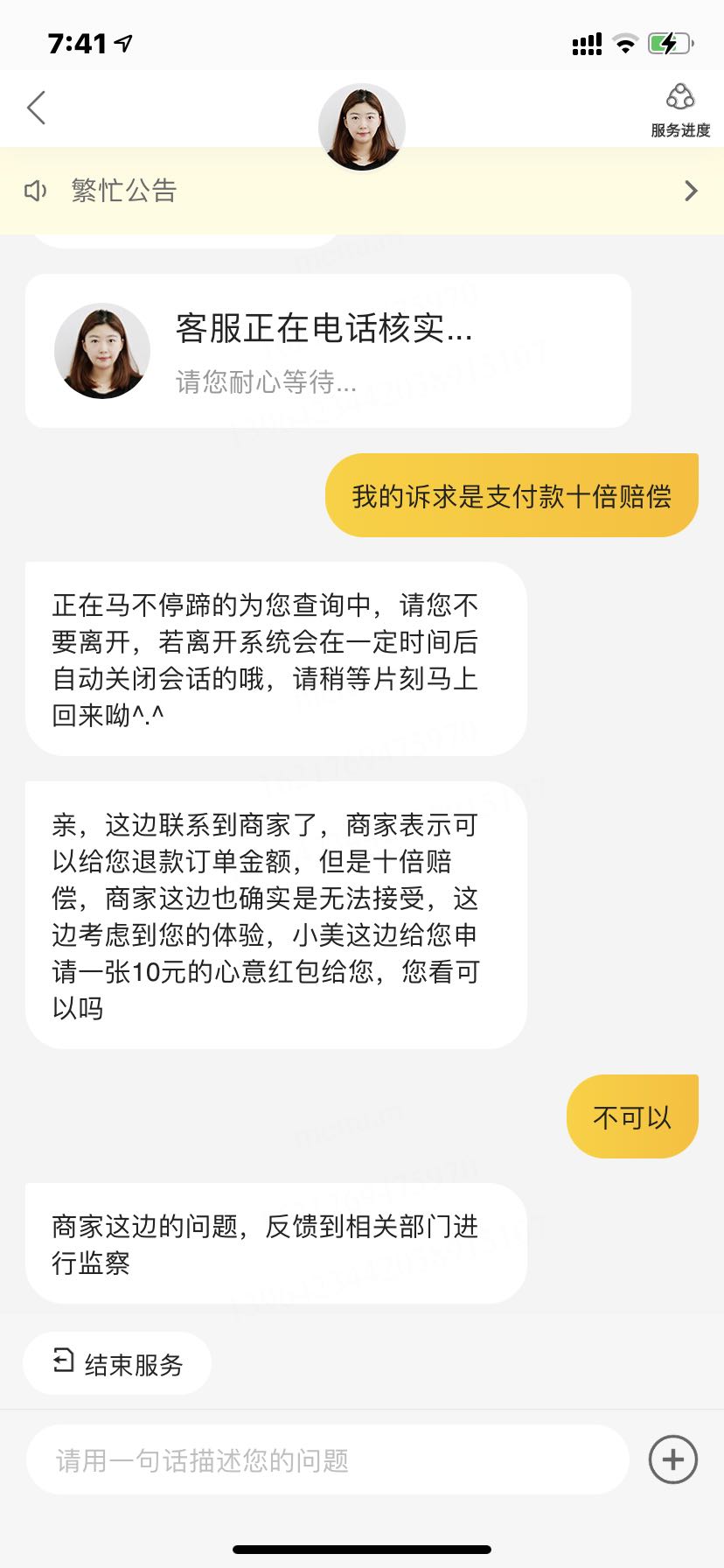
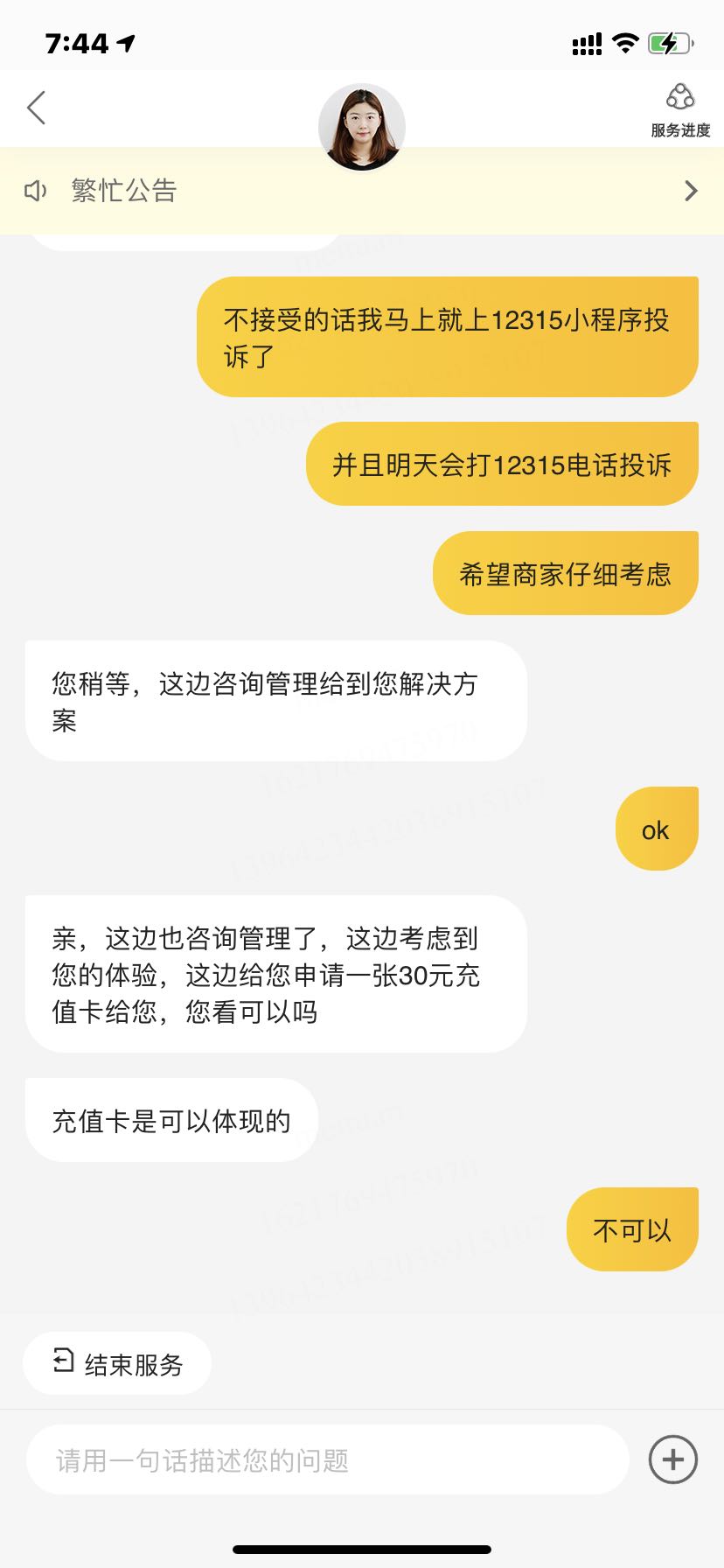
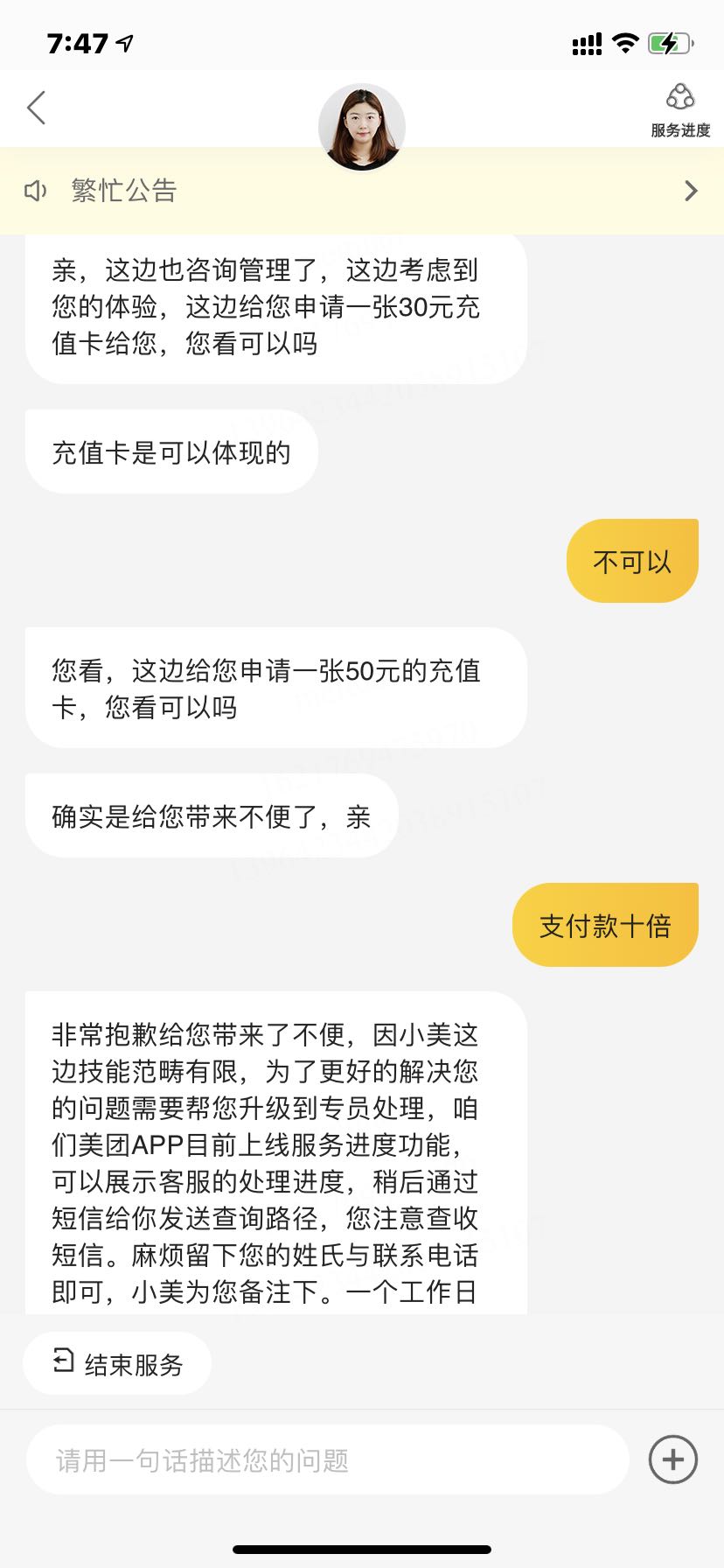
 ]]>
]]>
{kind=link}
{kind=link}